This article explains how to review crawler frequency, paths and abnormal visit
clues.
When to use
Use it to see whether search engine spiders crawl the site and whether crawl
frequency and paths match expectations.
Steps
-
Open the Spider Crawler page and review crawl records by crawler type.
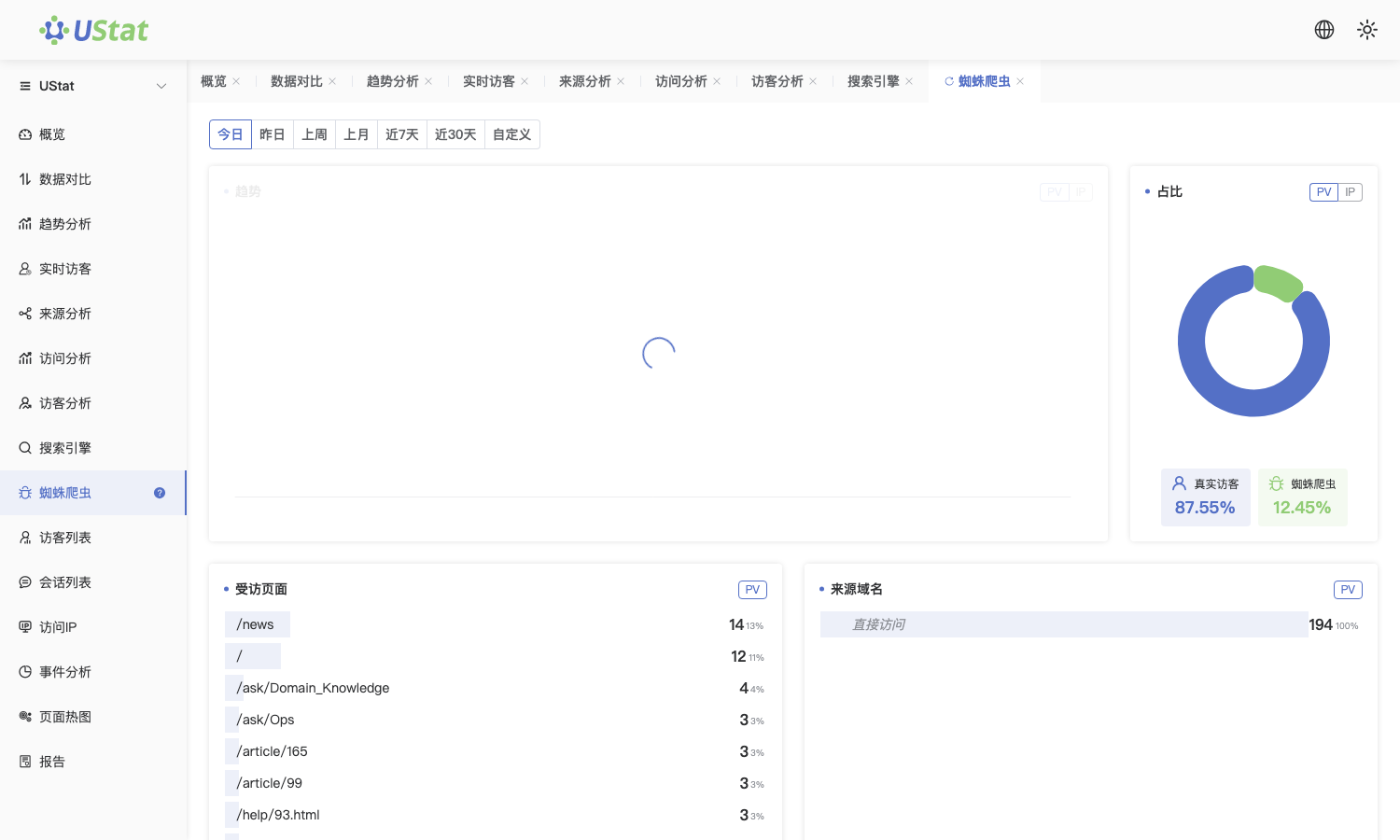
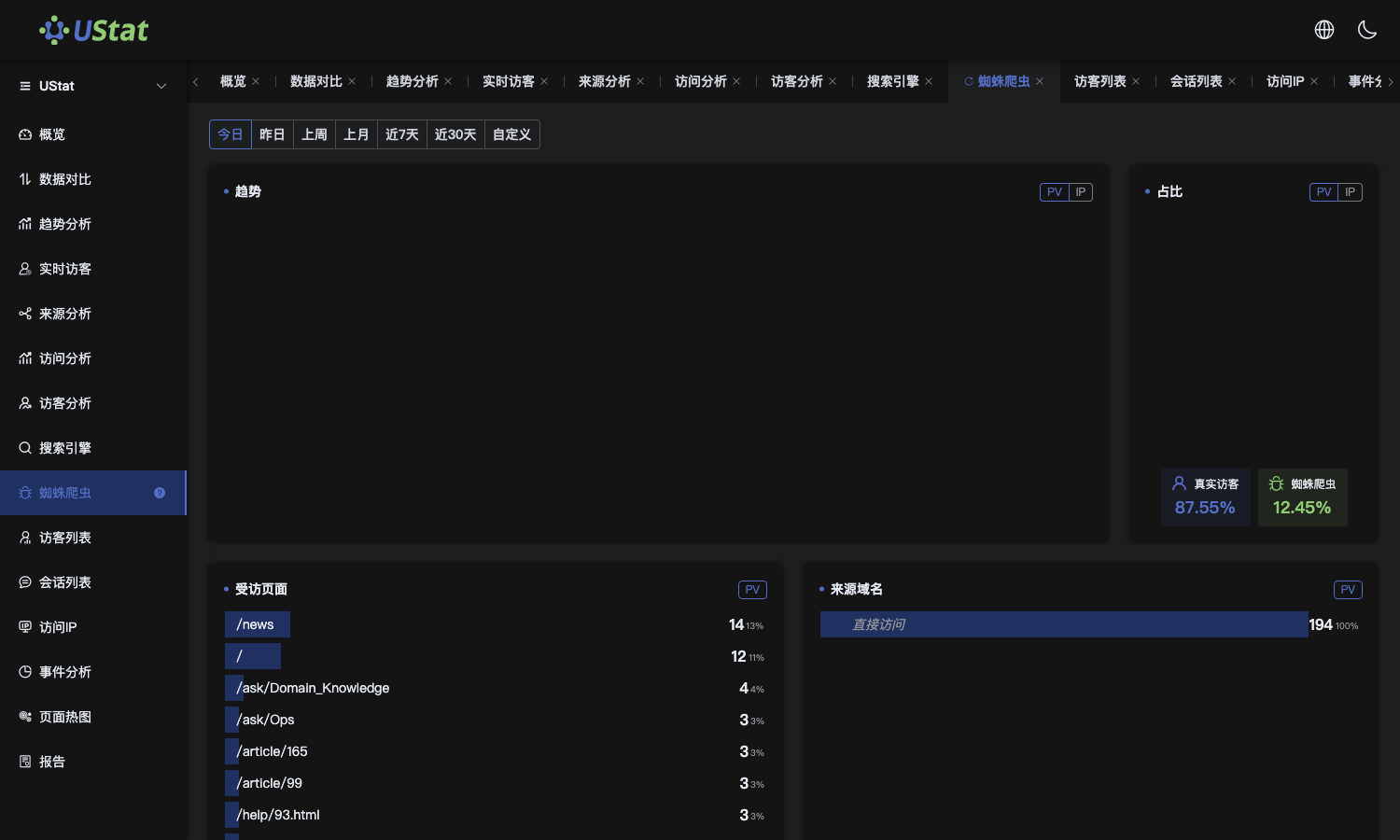 Interface example. Actual console display may vary.
Interface example. Actual console display may vary.
-
Focus on crawled pages, crawl time and frequency to judge whether
important pages are visited continuously.
-
When important pages are not crawled for a long time, check internal
links, robots rules, status codes and login requirements.
-
When crawl frequency suddenly rises, first verify whether it relates to
site updates, sitemap submission or search-platform crawling.
Notes
-
This article focuses on automated crawl records and does not evaluate
visitor conversion.
-
Indexing and ranking conclusions should be verified with search platforms.