蜘蛛爬虫
🕷️ 功能模块:蜘蛛爬虫
📍功能入口:
登录 UStat 进入查看网站统计数据后,在左侧导航栏点击【蜘蛛爬虫】,即可进入该模块。
🧩 功能介绍:
“蜘蛛爬虫”模块专为分析各类搜索引擎爬虫(又称网络蜘蛛、Spider、Bot)对网站的访问行为而设计。通过该功能,您可以了解不同搜索引擎的抓取频率、偏好页面,以及是否存在异常的爬虫活动。
它在以下场景尤为重要:
- SEO 抓取状态检查(是否被搜索引擎有效识别与收录)
- 抓取过频或恶意爬虫识别
- 防刷、反作弊、安全防护前置监控
- 网站结构优化(例如 sitemap 设置效果观察)
📄 页面结构说明:
- 顶部时间筛选条
- 同样支持“今日、昨日、本周、本月、近7天、近30天、自定义”等时间范围选择
- 所有爬虫数据将随时间更新
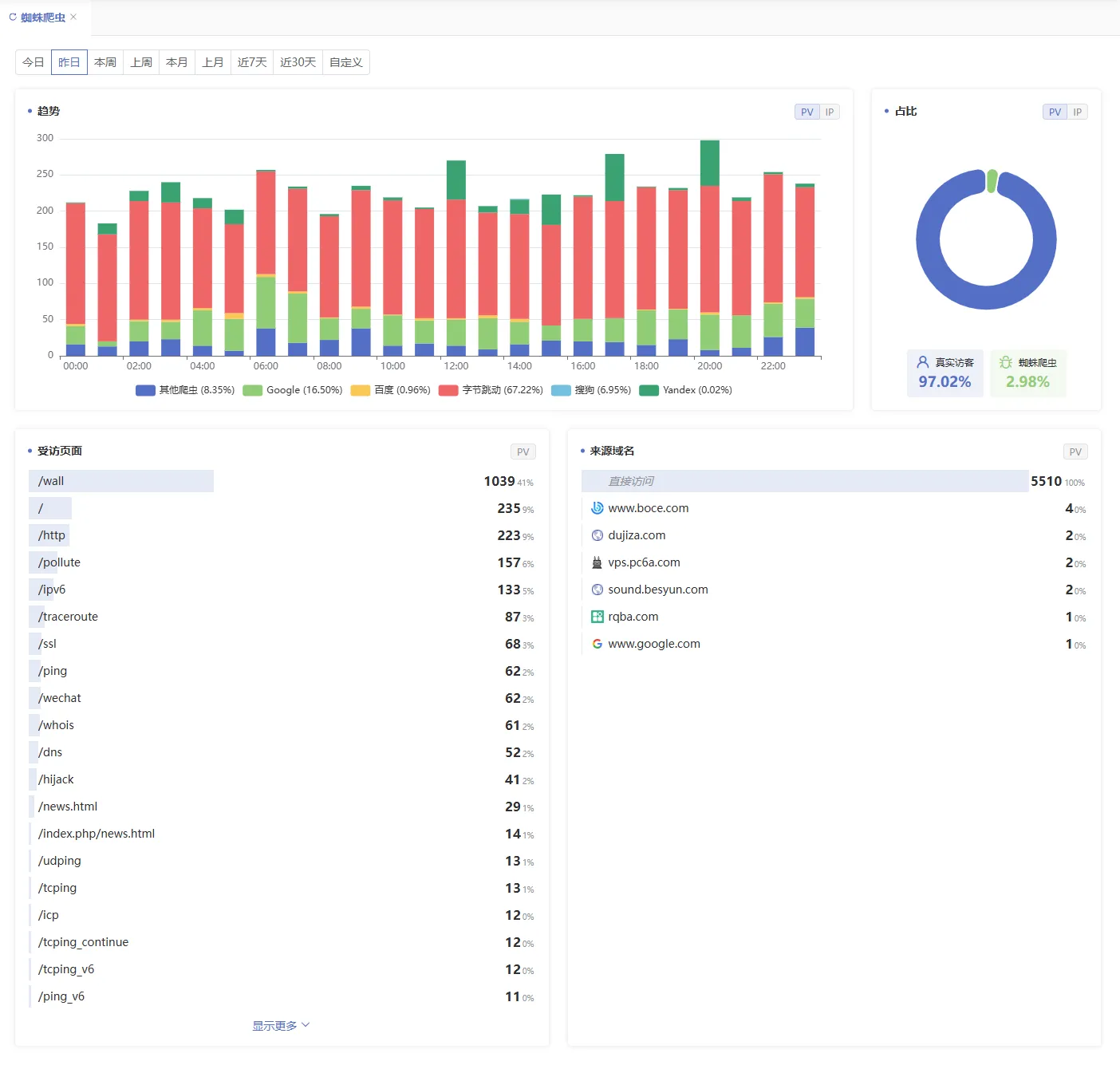
- 爬虫访问趋势图(柱状图)
- 展示不同搜索引擎爬虫(如:Googlebot、Baiduspider、Bingbot 等)在选定时间内的访问次数走势
- 有助于查看网站是否处于被频繁抓取或几乎未抓取的状态
📊 可辅助判断收录活跃度和结构友好性。
- 真实访客与蜘蛛爬虫占比图(饼状图)
- 展示真实访客与蜘蛛爬虫的占比数据
4. 受访页面与来源域名列表
- 展示受访页面明细与来源域名地址
📘 衍生术语解释:
- 蜘蛛(Spider)/爬虫(Crawler):搜索引擎自动程序,定期访问网站页面并收录其内容
⚙️ 可操作项说明:
- 点可在图表中点击PV、IP切换展示
✅ 使用建议:
- 若发现某类搜索引擎抓取量激增,应评估是否发布了新内容、增加了外链,或 sitemap 文件更新;
- 若出现未知爬虫、重复抓取无关页面等行为,可考虑屏蔽其 IP 或设置反爬虫规则;
- 若重要页面长期未被抓取,建议优化内部链接结构或提交 sitemap;
- 可与【搜索引擎】模块配合使用,判断爬虫抓取行为是否带来了实际访问流量(即是否有效收录)